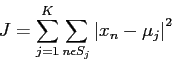Next: Análisis cualitativo de los Up: Procesamiento del lenguaje natural Previous: Aprendizaje no supervisado: Jerárquico
K-means es un algoritmo propuesto por MacQueen en 1967 que
plantea el agrupamiento de ![]() elementos de datos en torno a
elementos de datos en torno a ![]() centroids aleatorios en forma de subgrupos
centroids aleatorios en forma de subgrupos ![]() conteniendo
conteniendo ![]() puntos de datos, a medida de minimizar el criterio de suma de cuadrados
como vemos en la ecuación (
puntos de datos, a medida de minimizar el criterio de suma de cuadrados
como vemos en la ecuación (![]() )
)
donde ![]() es un vector representando el
es un vector representando el ![]() -esimo punto de dato
y,
-esimo punto de dato
y, ![]() es el centroid geométrico de los puntos de datos
es el centroid geométrico de los puntos de datos
![]() .9 (Véase el algoritmo
.9 (Véase el algoritmo ![]() 10)
10)

El algoritmo puede ser afectado significativamente por el inicio aleatorio
de los centros, por lo tanto puede ser llevado acabo varias veces
para minimizar el efecto. El problema se encuentra en que el algoritmo
no logra el objetivo del mínimo global de ![]() sobre las asignaciones.
sobre las asignaciones.
julio 2010-03-26